|
|
- Blog |
- Microservices and Databases: The Main Challenges
Database Automation
Microservices and Databases: The Main Challenges


Microservices and Databases: The Main Challenges
What You’ll Learn:
- Understanding microservices architecture and its benefits
- Key challenges in managing microservices and databases
- Best practices for microservice implementation
- Automation solutions for optimizing microservice ecosystems
Microservices Explained
Microservices are decoupled software components that run individual business processes or single services, typically integrating with well-known interfaces like APIs and possessing their own data storage. This architecture allows organizations to work on new features while leaving legacy systems intact.
Microservices vs. Monolithic Architecture
Microservices break down business processes into smaller, separate components, unlike monolithic architectures which operate as a single, indivisible unit. Companies are transitioning to microservices due to their flexibility, scalability, and ease of maintenance. While monoliths can be simpler to develop initially, they become increasingly complex and difficult to modify as they grow.
How Microservices Enhance Scalability and Resilience
Microservices architecture improves system scalability and resilience by allowing independent deployment and scaling of individual services. This approach ensures high availability and fault tolerance, as issues in one microservice don’t necessarily affect the entire system.

The Benefits of Using Microservices
Implementing microservices offers numerous IT and business benefits, including:
- Eliminating the need for legacy migration
- Enabling independent releases
- Improving modularity and reducing interdependencies
- Empowering smaller teams to develop and deploy new services
- Responding faster to changing market needs
Real-World Examples of Microservices in Action
Companies like Netflix and Uber have successfully implemented microservices architecture. Netflix’s transition to microservices allowed them to handle millions of concurrent streams efficiently, while Uber’s use of microservices enabled rapid scaling of their ride-sharing platform across multiple cities and countries.
Overcoming Common Monolithic Limitations
Microservices address several challenges posed by monolithic architectures:
- Deployment issues: Microservices can be deployed independently, reducing the risk and impact of updates.
- Development bottlenecks: Teams can work on different services simultaneously, accelerating development cycles.
- Scalability constraints: Individual services can be scaled as needed, optimizing resource utilization.
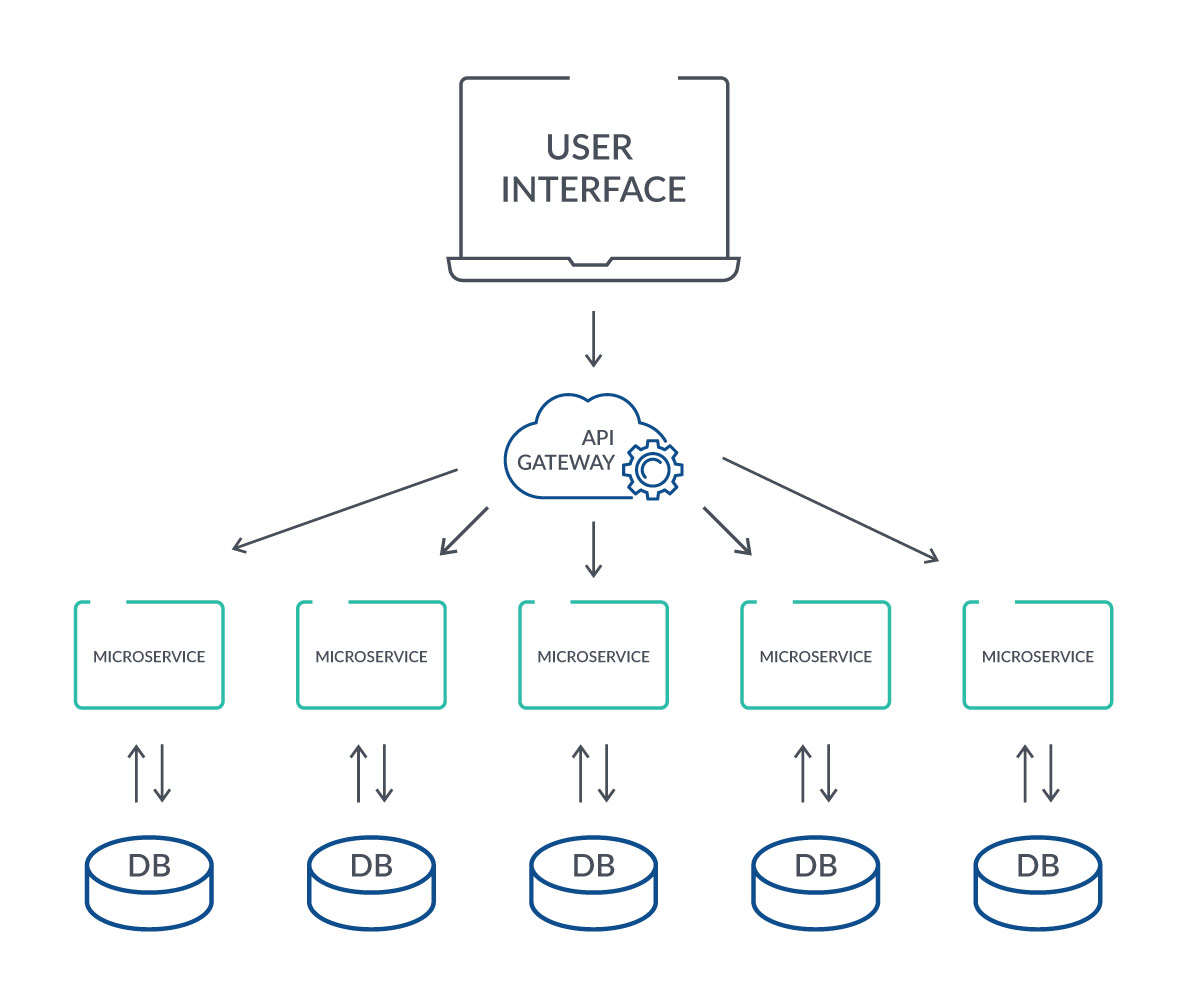
A typical microservice ecosystem
In a microservice ecosystem, each service is a semi-independent entity with its own database, allowing for separate releases and management:
Modern Tools and Technologies in Microservices
Key tools and technologies in microservices architecture include:
- Kubernetes for container orchestration
- Docker for containerization
- Kafka for event streaming
- NoSQL databases for flexible data storage
Best Practices for Managing Microservice Interactions
Effective communication between microservices is crucial. Best practices include:
- Using well-defined APIs for service-to-service communication
- Implementing message brokers for asynchronous communication
- Adopting the Circuit Breaker pattern to handle service failures gracefully

Microservices and Databases: The Main Challenges
There are 3 main parameters that need to be taken into consideration and taken care of while developing and deploying microservices:
1. Read and Write Performance
Read performance is measured by operations per second or a combination of query speed and result retrieval time. Write performance is typically measured by the number of write operations per second.
Pro Tip: Boost read performance by combining indexing with caching tools like Redis or Memcached. This reduces database load and accelerates query response times for high-demand operations.
2. Efficiency
Low-latency databases are crucial for delivering instant user experiences. For read and write operations, low latency is typically under 1 ms, while high latency is over 10 ms.
3. Data Sharing
Each microservice’s persistent data should be private and only accessible via its own API. When multiple services need to share data, consider encapsulating it within a dedicated service or using event-driven mechanisms for replication
Automation: The Ultimate Solution
Automation is essential for managing the complexities of microservices and databases at scale.

Benefits of Automation in Database Management
Automation in database management offers several advantages:
- Improved consistency across environments
- Enhanced scalability through automated provisioning
- Faster fault detection and resolution
Best Automation Tools for Microservices and Databases
Some top automation tools include:
- DBmaestro for database release automation
- Liquibase for database schema version control
- Flyway for database migrations
How to Integrate Automation into Your CI/CD Pipeline
Integrating automation into your CI/CD pipeline involves:
- Selecting appropriate automation tools
- Defining automated processes for database changes
- Implementing automated testing for database operations
- Setting up monitoring and alerting systems
Pro Tip: Automate schema changes with tools like DBmaestro to streamline updates and minimize downtime, ensuring consistent performance across all microservices.
Key Takeaways:
- Microservices offer improved scalability, flexibility, and maintainability compared to monolithic architectures.
- Managing microservices and databases presents challenges in performance, efficiency, and data sharing.
- Automation is crucial for optimizing microservice ecosystems and database management.
- Implementing best practices and leveraging modern tools can significantly enhance microservice architecture effectiveness.
Get your demo now
Related Articles

IBM’s Project Bob and DBmaestro – A Match Made in Heaven