Democratizing Data with DataOps: The Key to Digital Transformation


As you already know, DevOps accelerates the build lifecycle with the help of automation. It focuses on software Continuous Integration and Continuous Delivery (CI/CD) by leveraging on-demand integration, testing, and deployment of code. This eventually reduces time to deployment, decreases time to market, improves quality, and shortens mitigation times.
The same methodology is now being applied to optimize merges, builds, and releases for data, also known as DataOps (Data Operations).
Data Democratization: Empowering Organizations
Just like DevOps did a decade ago, DataOps is also helping streamline data cycle processes and polish corporate culture.
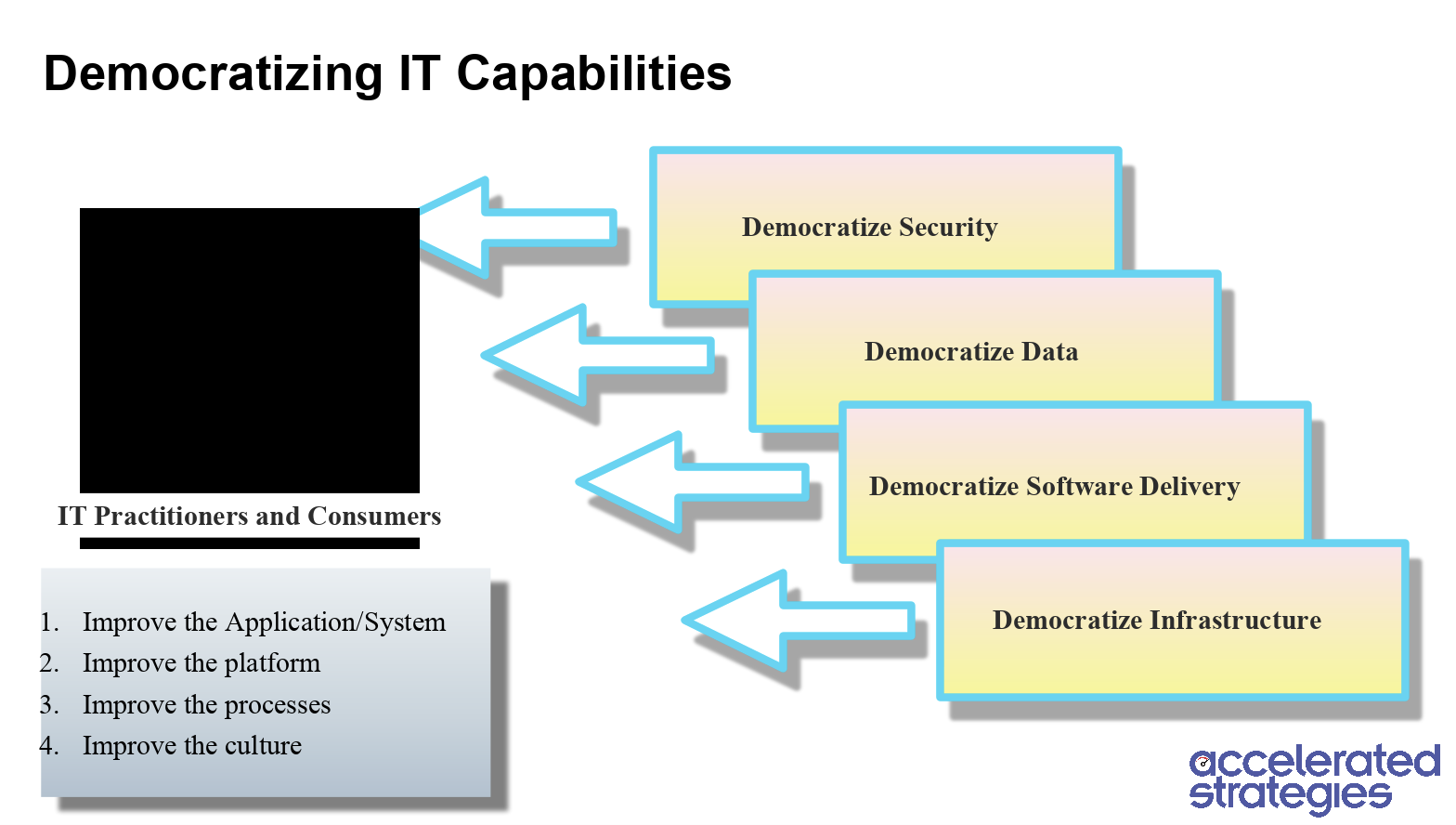
- Democratize Security – Your data goes through many storage, compute, and analytic environments, with each touchpoint introducing new security risks. The most effective way to reduce this risk is to implement automated governance rules and workflows that are applied across the entire data pipeline. DataOps platforms coupled with database automation are doing just that.
- Democratize Data – DataOps and Data Democratization are promoting a huge shift in the way organizations think and operate by promoting “self service”. Gone are the days when stakeholders needed to send emails and engage the IT teams and data experts to get the job done. Hooking up to data repositories like Snowflake and using tools like Tableau has never been easier.
- Democratize Software Delivery – As previously explained, DevOps is the driving force behind the DataOps revolution. Data Democratization requires the infrastructure to support scalability and support multiple environments. When you have a sound DevOps ecosystem that is pushing high performance CI/CD pipelines and enabling automated governance, you are already halfway there.
Unfortunately, there is a missing link – the database. This crucial aspect is often overlooked and remains siloed. Don’t worry, we have you covered on this one.
FREE ON-DEMAND WEBINAR
Achieving DevOps for the Database: Speed Without Disruption
Barriers to Data Democratization
DataOps has enabled data elasticity and faster data movement, but what about security and governance? Moving faster is a double-edged sword in the sense that organizations now have to face challenges related to controlling, tracking, and auditing changes being made to their applications. Things get even more complex when it comes to the “configuration-sensitive” database.
Here are some technical barriers that organizations are facing today while scaling up fast and implementing DataOps without proper governance.
- Data Inertia – With multiple data streams being added to your data models and SaaS applications bringing in even more information, you are looking at massive data volumes to deal with on an ongoing basis. This can lead to provisioning costs and delays, not to mention the risk management issues and regulatory burdens that escalate fast.
- Data Complexity – Data is everywhere – a great advantage when harvested and managed properly, but this isn’t always the case. You have dormant data in legacy systems, there is data in the cloud, and you have the incoming streams. How do you make sense of all this? Most traditional or hybrid workflows simply cannot handle such a big data influx smoothly.
- Data Silos – It’s not just about the volume. The modern organization has to deal with siloed data. You are probably looking at packaged applications, zero-touch production systems, or just external streams with formats you cannot integrate. Then you also have toolchain incompatibilities, not to mention organizational and cultural silos.
Database Release Automation: Promoting Self-Service
Self-service is at the core of DataOps and Data Democratization. But how can it be achieved? Database release, security, and governance automation is the simple answer. Only allowing the DBA to shift his focus from managing deliveries (and solving issues) to security and quality can solidify the entire DataOps process.
Our recent research showed that the number of database failures and crashes go up as the database change frequency rises – a big DataOps problem.
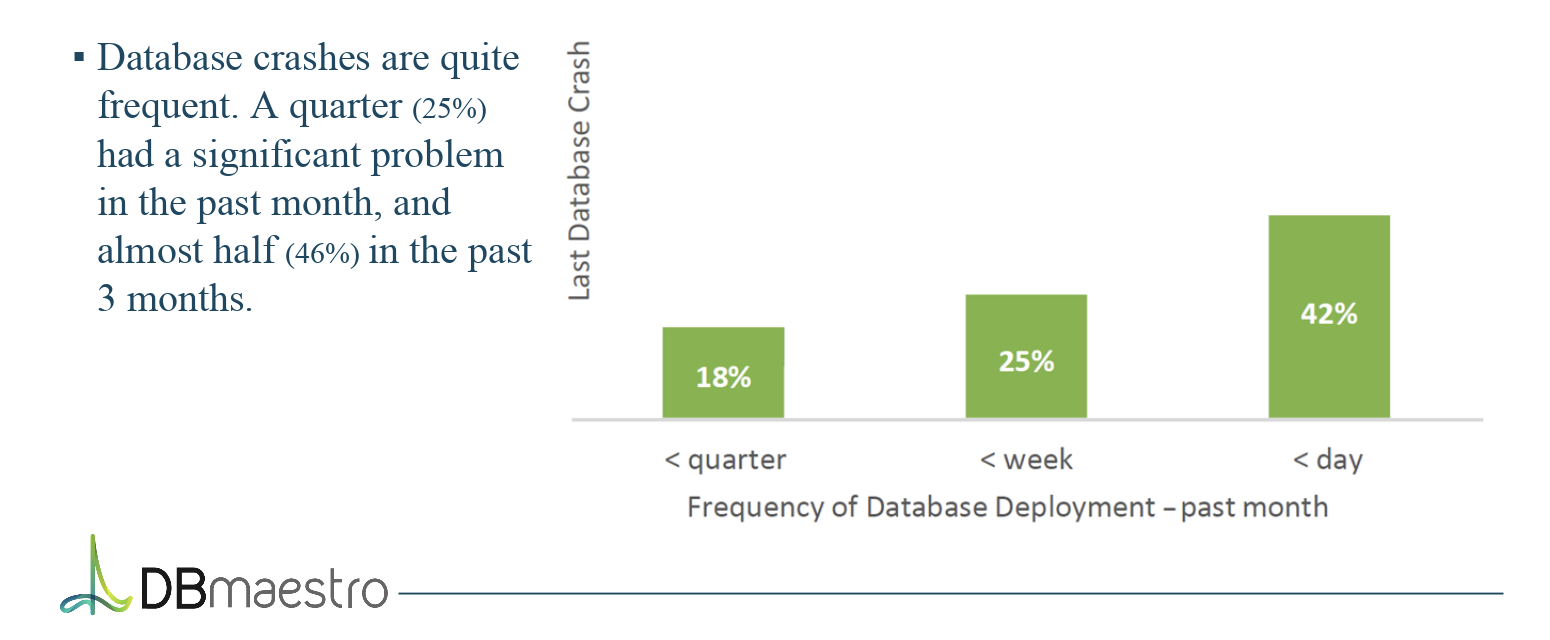
There is no denying the fact that your database release pipeline is the biggest enabler of data self-service today. To achieve this, you need to automate all database releases and make this a repeatable process, just like with your applications development pipeline. This should be complemented by testing, dry-runs, and traceability to ensure smooth rollbacks when needed.
Self-service doesn’t stop there. Database automation also helps with:
- Role and Permission Management – Your organization can’t afford to drive self-service without proper controls. A database governance solution will help you enforce roles and responsibilities, while also being to manage them from one centralized dashboard. The bottom line – limited access to sensitive data or critical environments.
- Guardrails – The need for speed is real. But doing so without proper database safeguards can result in a wide range of issues, with configuration drifts being the most common one. Proper drift management and code validation are mandatory if you want to create a smooth DataOps pipeline before you start breaking things.
- Regulation and Compliance – With data privacy regulations like GDPR, HIPAA, and SOX in full effect, you need to make sure that you are creating audit trails for all database operations – automatically. If you cannot track who created the code, who made the changes, who packaged it for release, and who hit the “Go” button, you can be in deep trouble.
Organizations can now democratize database access without compromising security with DBmaestro. Click on the link below to see how it works in real-time.


