 |
|
- Blog |
- 4 Team Foundation Server Limitations & What to Do About Them
Database DevOps
4 Team Foundation Server Limitations & What to Do About Them


Team Foundation Server (often abbreviated to TFS) is a Microsoft product designed to assist with your source control, reporting, project tracking, workflows and collaborative software development needs. It’s a powerful and much beloved change management solution. But it’s not without its limitations.
While it’s very popular with end-to-end “Microsoft shops” – companies relaying on Microsoft for most of their infrastructure and development efforts – it’s somewhat lacking when it comes to database version control; an issue that is amplified in IT environments that are not Microsoft shops.
I compiled a list of 4 common Team Foundation Server limitations that beset DBAs and developers when working with TFS database tools.
1. Process control and validated change capture
Preventing out-of-process changes is a big deal. When anyone can access the database and introduce changes as a part of application development or debug stage, how can you make sure that these changes actually find their way into the repository?

There are many times you can’t. As a result, your application may pass and be promoted the next deployment environment on to fail there (hopefully not in production).
2. The sandbox and collaboration experience
Another pain point that often comes up is the complexity required to work on sandboxes and the challenge of working on shared databases. Working on sandboxes – local databases, one for each developer – while well supported, requires a lot of maintenance, syncing (basing and re-basing of changes back and forth against the integration environment) and excessive, progress inhibiting merging.
In many cases, you’ll want to work out of a shared database – team centric, project centric, edition centric, etcetera – as it allows several developers to cooperate on the same project. But these databases are not protected and anyone can easily override anyone else’s code.
So whichever way you go, you’re likely to have some troubles.
3. Content management
While content management functionality exists in TFS, it’s not reliable, does not recognize changes well, and often requires manual implementation. These TFS limitations are no trifling thing.
Reliable and scalable (automatable) change recognition across content is essential for dealing with all the lookup tables and dictionaries that serve the application. Put bluntly, it’s a prerequisite to good database source control.
4. Interoperability
Developers and DBAs would much rather work with the SQL Server Management Studio (SSMS) IDE but are driven to work with the SQL Server Database Tools (SSDT). Speaking from personal experience as well as on behalf of the many many DBAs I talk to, this can be really annoying and slow the pace of release.
Of course, these are not knocks on TFS per say, but simply a delineation of where TFS’s capabilities end in terms of database version control.
The best workarounds, in my experience, are usually found via purpose-created solution integrations. The DBmaestro Database Source Control tool, for example, extends the check-in/check-out metaphor to database objects so no out-of-process changes are even possible.
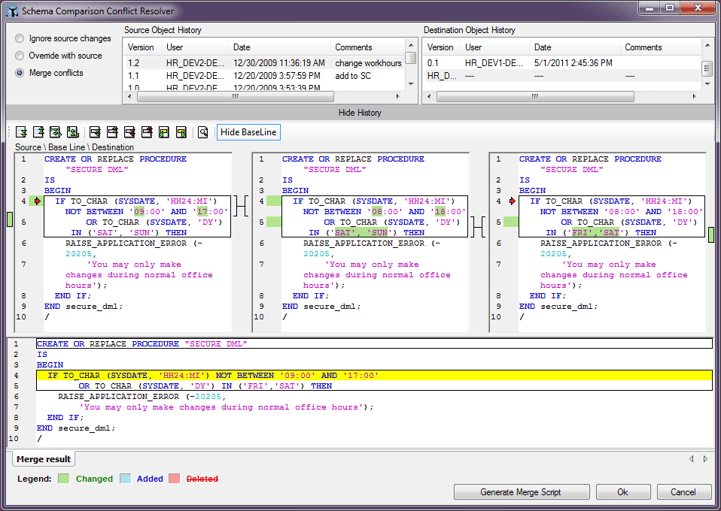
With this automated control layer in place, database schema objects are locked (in read-only mode), until a developer actually checks-out an object and then makes a change to it. The developer can then check-in the new object, which locks it again.
A sufficiently robust integration solution must also be able to deal with complex environments (sandboxes, shared environments, or any combination), while managing control of content from relevant tables and doing so through the popular SSMS (and Visual Studio as well).
To ensure seamless coordination between change management software efforts conducted within TFS, and the back-end databases they impact, an appropriate solution must easily integrate with TFS. DBmaestro’s Platform of solutions are designed for convenience, efficiency, database security, scalability, and interoperability. Integrating such solutions with TFS is a surefire way to provide a more complete and more functional range of capabilities to facilitate your software project development and deployment.
Another function that ought to be considered when looking for an all-inclusive workaround is impact analysis. This is critical to ensuring that branch and merges are attended to and potential conflicts are caught and resolved. It’s also tremendously helpful to know what was changed when feature X was developed or bug Y fixed – from a code and database perspectives. In this way, a single, unified deployment process can be easily achieved based on Microsoft TFS definitions (activities and work items).
It’s worth repeating the fact that Team Foundation Server is a wonderful tool and this article is in no way intended to besmirch it. Still, the fact is that even the best tools have their limitations and it’s only in knowing those limitations (indeed, in scrupulously mapping them) that you can mitigate any adverse impact conferred upon you or your operation.
With the integration of a robust database change management and automation tool, you should be able to more effectively leverage the full range of TFS’s powerful capabilities. In this way, you can avoid the unpleasantness of running into walls in the heat of the daily DevOps battle. And at the end of the day, that’s really the goal: never slowing down and continuously delivering!
Get your demo now
Related Articles

Scaling Elite Software Delivery: A Blueprint for Modern Engineering

Agentic Database DevOps: From Automation to Controlled Execution
