Part 1: Agile Database Development
Business needs are the most significant driver of change. The ability to do more with less and offer accelerated delivery is what differentiates successful, world-class companies from the rest.
If your competitor can deliver relevant features, faster and with better quality, you’re eventually going to lose market share. Agile development was born from the need to move more rapidly and deal with ever-changing requirements, while ensuring optimum quality in spite of resource constraints.
Why Agile?
The waterfall methodology‘s big release concept doesn’t cut it anymore – you just can’t wait six months until the next roll-out or release. Agile database development methodology on the other hand is built for more rapid, smaller, and more iterative releases, allowing the development team to complete them faster.
Of course, the impact radius of changes is also far less than with bigger, more waterfall releases. Agility is what is expected from technology companies and IT divisions to support their business needs.
The next natural step was to link development with operations. Voilà, there’s DevOps!
How Agile?
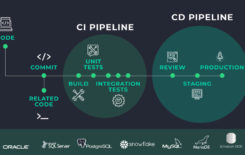
To effectively master Agile sprint deployments and to practice DevOps, you need to be able to implement deployment and process automation internally within development and QA, or to production. Otherwise, deployments and releases will require manual steps and processes, which lack repeatability, are prone to human error, and cannot be executed with high frequency.
The automation required is based on a version control repository that manages all software assets ready to be built (compiled) and then deployed (executed) to the next environment.
Where Agile?
Of course, all these principles apply equally across the IT landscape. Databases, for example, long neglected in terms of management innovation and process supporting software, should be beholden to the same agile and DevOps norms.
In terms of agile database development lifecycle, the build process starts by cleaning the working space and getting the relevant files from the version control repository. This is a critical phase that prevents out-of-process changes, such as occur when developers save their changes directly in the build server working space, instead of checking-in their changes to the database version control repository.
This example may sound absurd because developers should know that if they do so, their changes will be lost, as the technological structure enforces the process. Shoulda coulda woulda, but it happens.
This phase also prevents the build phase from taking work-in-progress changes by referring to only those changes that were submitted to the version control repository in a check-in process. The version control repository acts as the single source of truth.