|
|
- Blog |
- Adapting Continuous Delivery Pipelines to Database Automation
Database Automation
Adapting Continuous Delivery Pipelines to Database Automation

Advantages of Building a Continuous Delivery Pipeline
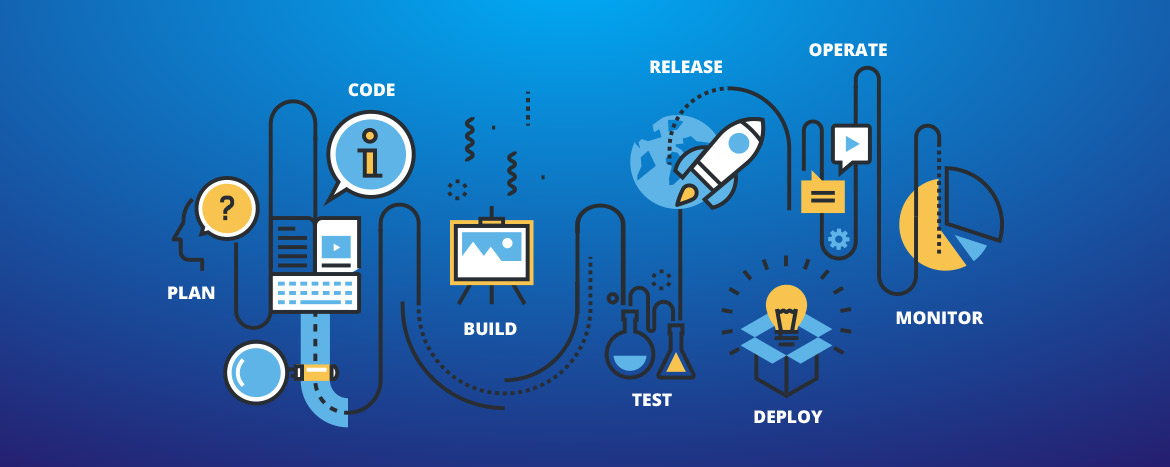
Continuous delivery pipeline stages are a series of steps that code changes pass through during an agile production process. A continuous delivery pipeline delivers products based on customer need and with the following essential advantages over manual processes:
- Quality – even when the pace of release quickens, quality is maintained
- Frequency – provides the ability to release whenever needed
- Predictability – all processes should occur as designed in the continuous delivery pipeline diagram, and when they don’t, a simple audit trail is provided
Once the minimum viable product from the agile continuous delivery pipeline is ready, it will execute as many times as required, with only occasional maintenance.
The continuous delivery pipeline also scales up or down while enabling incremental improvements but with minimal risk of a production crash. Teams can consistently rely on the process design of a continuous delivery pipeline because it is programmable. Of course, no software is perfect, so when errors occur, they can be quickly traced.
These advantages boil down to one main plus: reduced time to market through optimized development.

Improvements in software are often the result of many minor changes, and a continuous delivery pipeline is ideal for this purpose. Building a continuous delivery pipeline lets concepts become products through experimentation. A continuous delivery pipeline enables developers to produce even small and incremental batches of changes while minimizing failure-causing glitches.
These changes accumulate into features, and ultimately products, while maintaining security and accountability. If a change does not produce the desirable effect, it can be immediately replaced. Continuous delivery pipelines also reduce the mean time to resolve production issues and minimize downtime both for the enterprise and for customers.
When You Don’t Use a Continuous Delivery Pipeline…
Horror stories about failed upgrades are common, yet many development teams—including those in major organizations—often use legacy methods, even during deployment. Take, for example, the case of the Royal Bank of Scotland Group. A corrupt upgrade executed by the staff led to chaos throughout the bank’s branches. One customer, on life support in Mexico, almost had their machine disconnected because they could not pay through the banking system. It took almost a month to return to normal, and during the interim, there were government investigations, a huge loss of reputation, and enormous, avoidable costs, including eventual fines of £42 million.
Databases are very different from application code. Changes to the database must be logged before, during, and after deployment, while rolling back a database is usually far more complicated than deleting the last code change to an application.
A malfunctioning or bugged application release is an issue that can be reverted back to the previous version relatively easily in many cases. In comparison, the cost of an error is much higher for the database because it retains persistent content and cannot just be reverted to the old version. A database failure or hack can result in serious downtime, be harder to fix, and may ruin your company reputation in extreme cases. For instance, if you drop an index by mistake, rebuilding it may result in hours of super slow performance; if you drop a column or a table, you may never recover the latest customer information, even if you access your backups.
Similarly, the process of updating a database in increments (changing the existing database to fit a required structure) is very different than the process of updating or replacing application code. Incremental database changes require that you start using the same configuration as the previous version; otherwise, unexpected outcomes will result. And, because database changes are implemented manually in many cases, or patched out of processes to deal with an issue, configuration drift can become a problem.

Risky factors such as these have led to database changes being handled differently than application changes. In many organizations, database changes are either not included in the continuous delivery pipeline diagram, and/or go through a different deployment process. When the database is not included in the pipeline, many database changes:
- Are executed manually, which can be messy, risky and not fully repeatable
- Leave no audit trail
- Limit the use of continuous integration and continuous delivery
In other cases, enterprises apply a separate process to the database, and so the development team and the DBA team need close communication, which sometimes does not happen, leading to errors.
Complications resulting from database changes lead to a bottleneck in an agile continuous delivery pipeline, reducing time to market and negating the advantages of continuous delivery pipelines as experienced with applications. Additionally, errors resulting from incorrect configuration starting points, configuration drift, and manual procedures can result in a loop that is difficult to exit.
Although databases are very different from applications, changes to the database can actually be handled just as applications are in a continuous delivery pipeline.
Database changes can be executed with source control if they are described with scripts. Then, the database development process is capable of continuous integration and continuous delivery, and can be part of the continuous delivery pipeline. By using automation, standards of quality, frequency, and predictability come into play and the complications of database changes are reduced. Automation also minimizes the effects of human error and helps to increase the overall speed of production.
In short, databases and applications should be part of the same deployment pipeline and share the same development lifecycle. Database changes should thereby become routine and traceable, while an effective method of communication between the development teams and DBA teams must also be instituted.

Implementing database automation can start at virtually any point in the pipeline, although it is recommended to start from the left side of the deployment pipeline and move right while making incremental changes. Following are the first three steps:
- Initiate the description of database changes with a script
- Build and validate an artifact that includes the database changes (this is the first automated step, and leads to building the package, testing it, and uploading it to deployment or an artifactory management system)
- Fully automate deployment of all database changes
This steps are best handled by customized software and firms that specialize in database automation. They ensure a pain-free move to implementing the continuous delivery pipeline concept for database changes and provide valuable advice for changing the way your organization handles the database-application relationship.
DBmaestro is an industry leader in applying the principles of continuous delivery pipelines to the database. If you’re interested in making development and databases as problem-free as possible, contact us today.
Get your demo now
Related Articles

IBM’s Project Bob and DBmaestro – A Match Made in Heaven